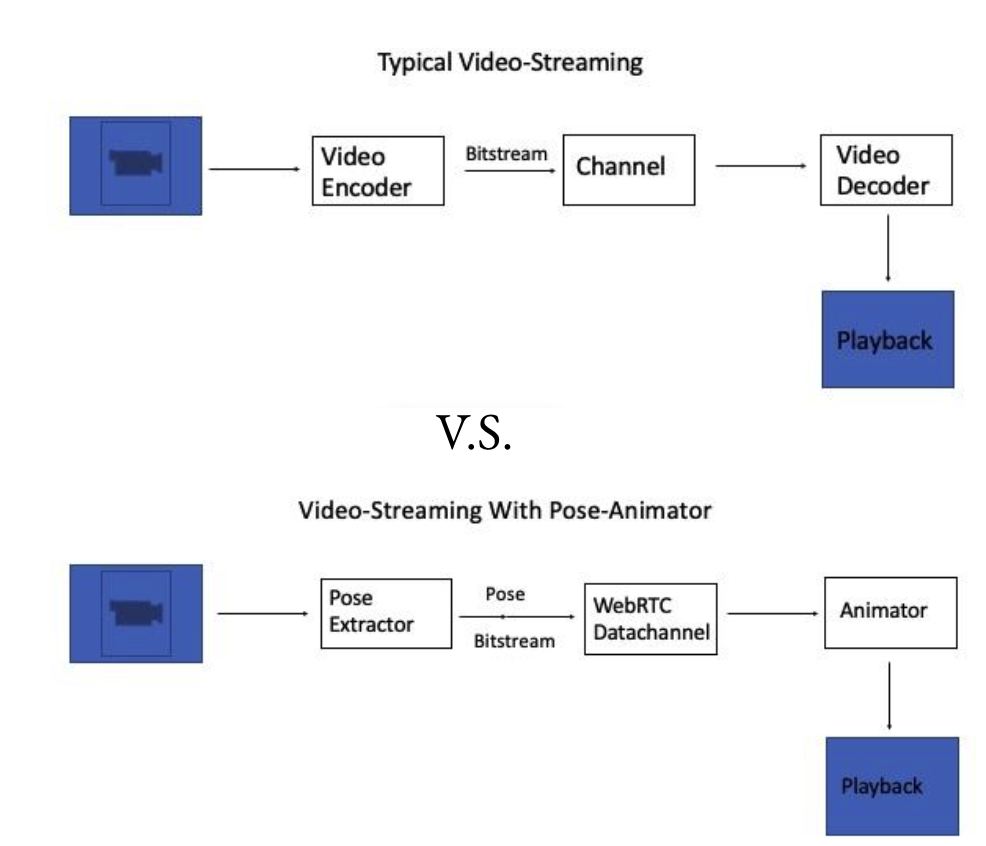
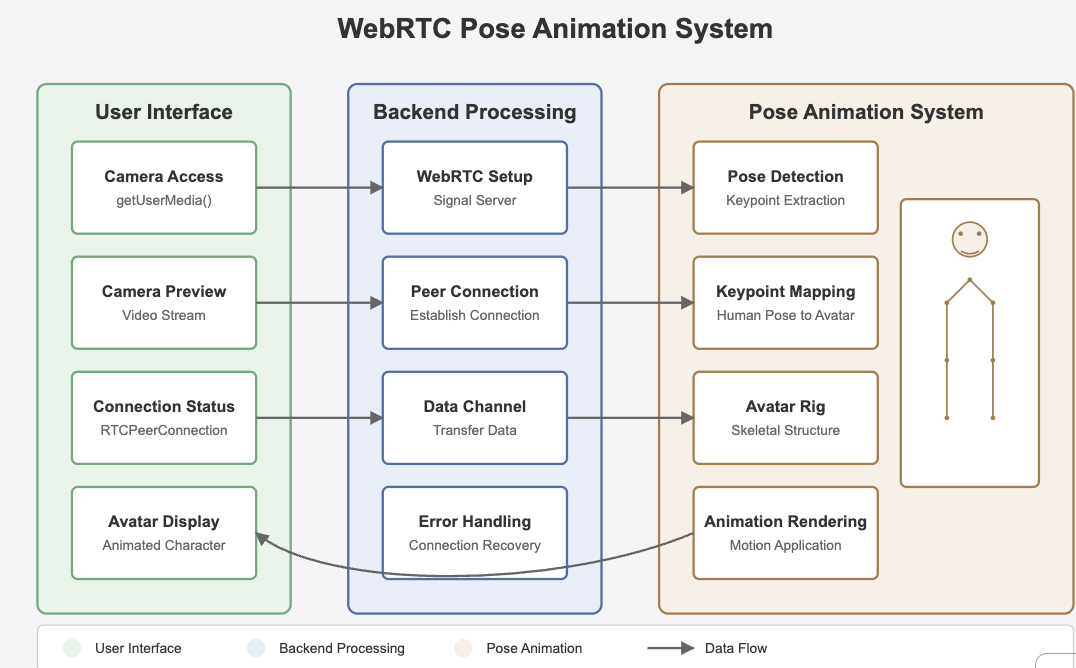
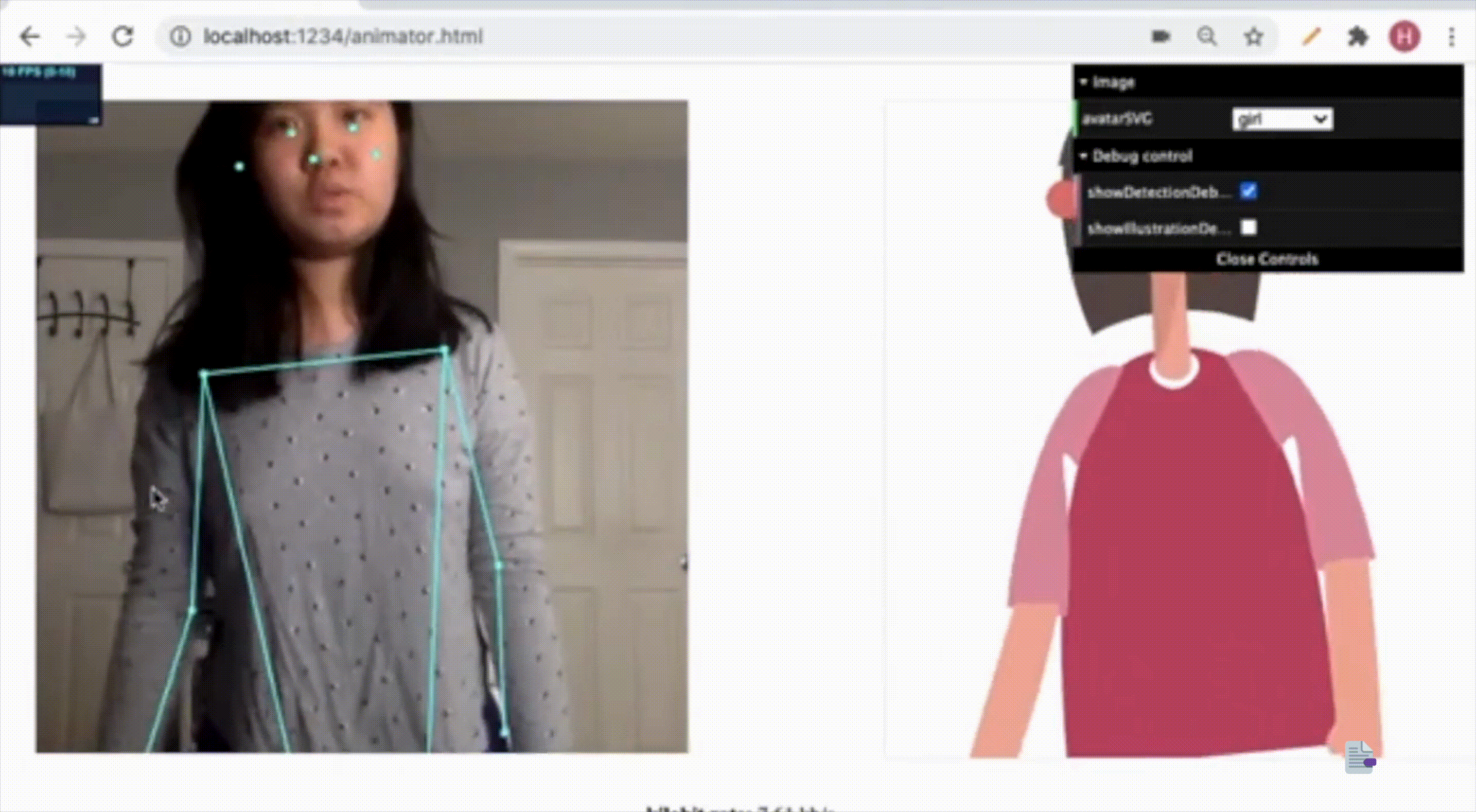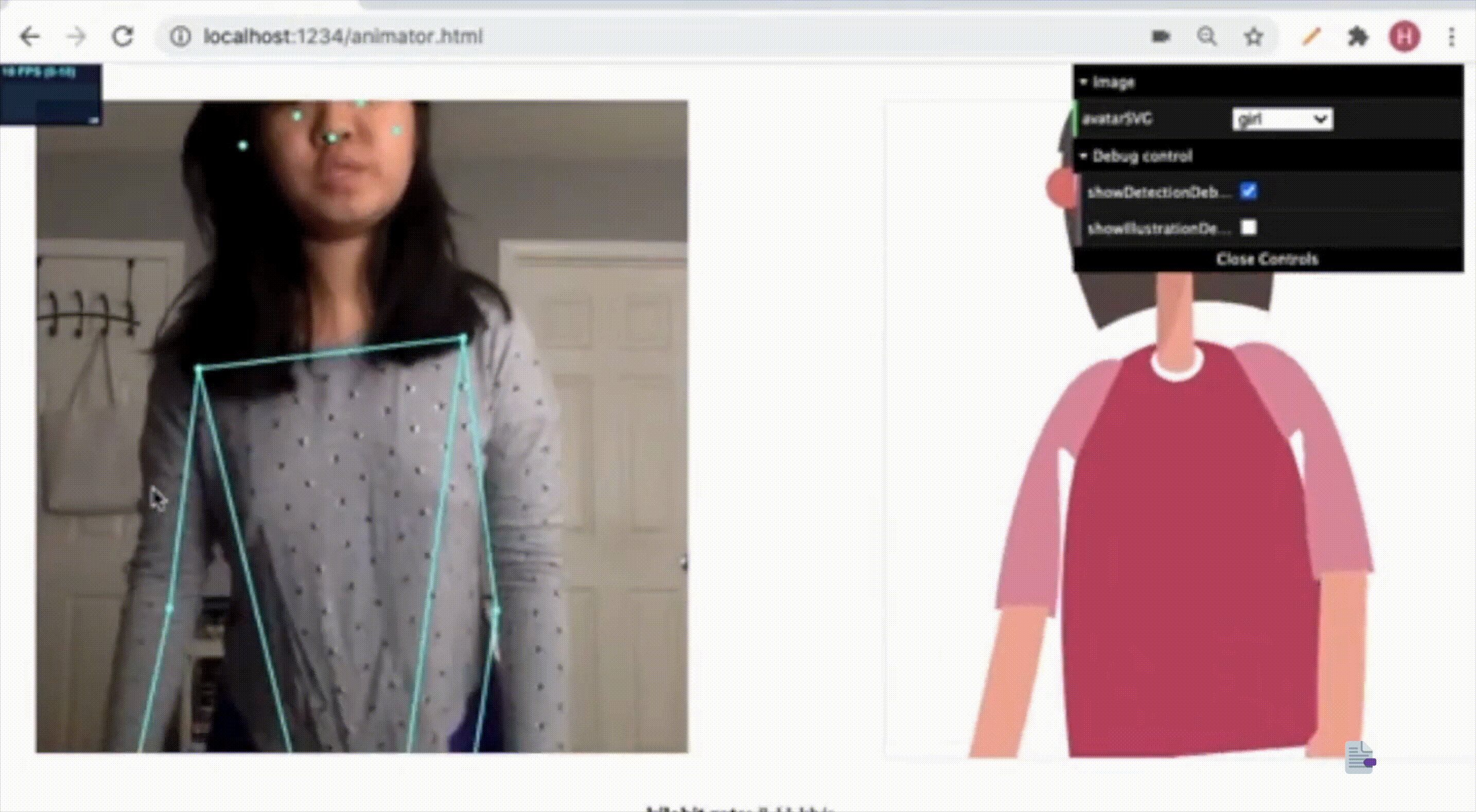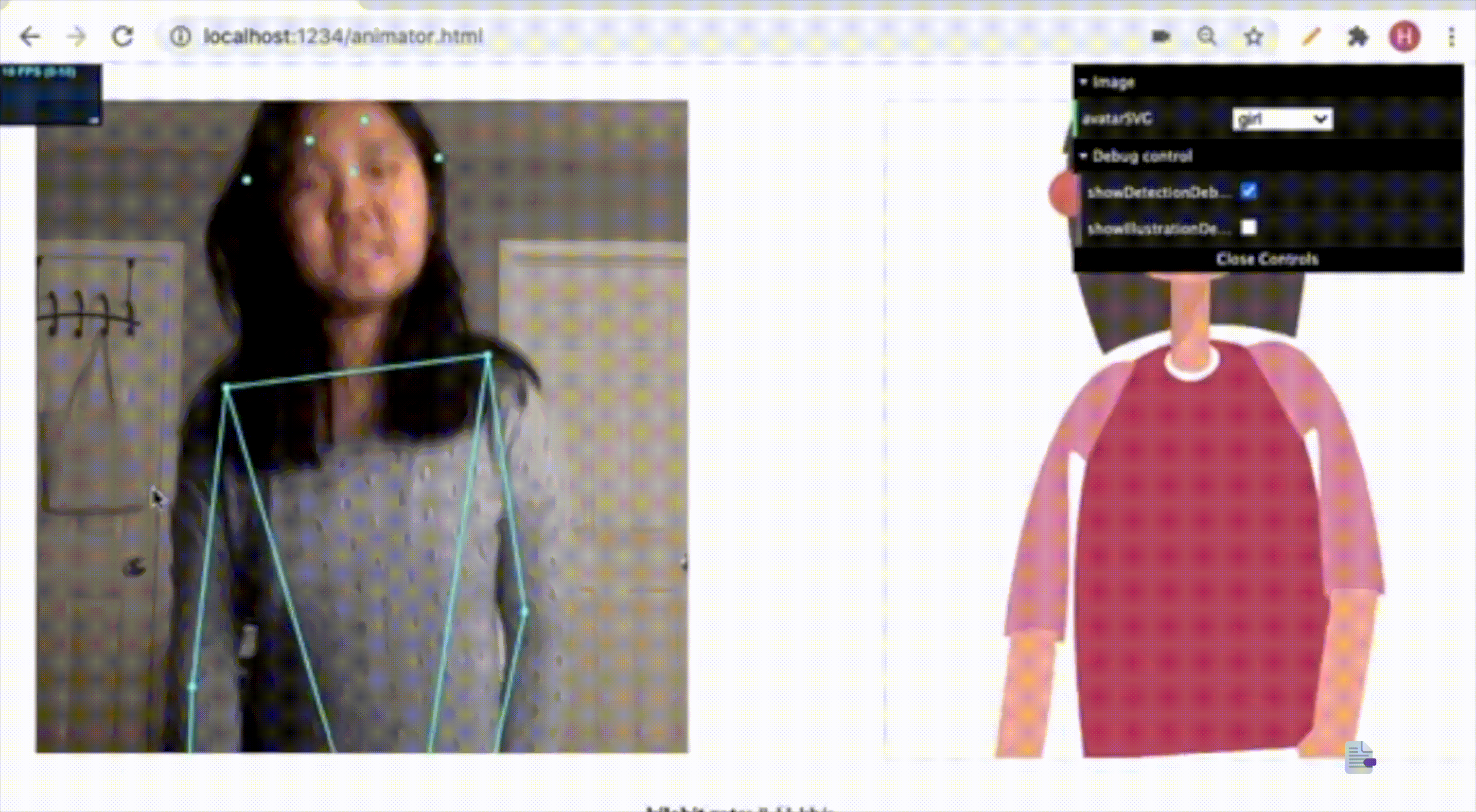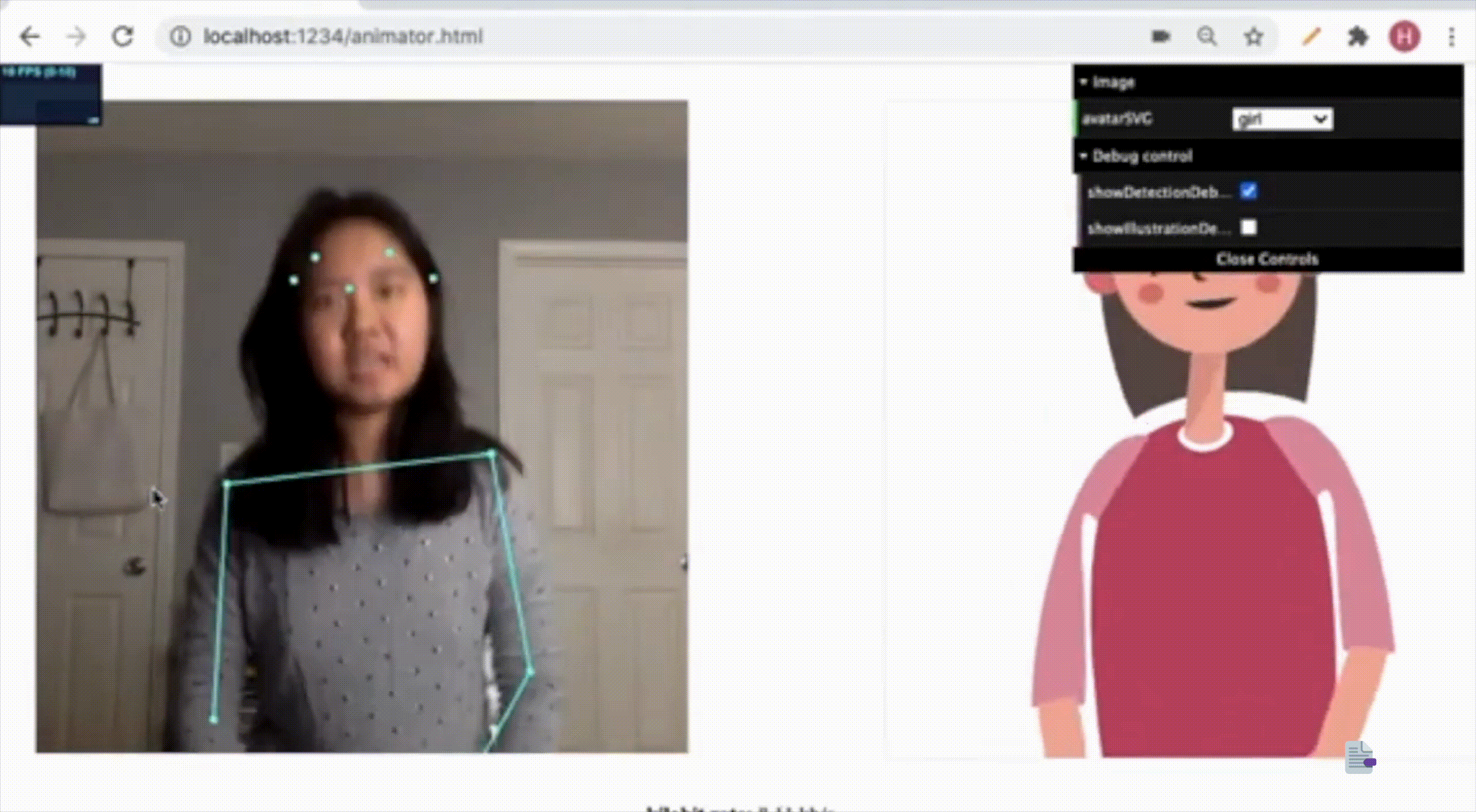
During the COVID-19 pandemic, video communications became an essential mode of information exchange. Our research team focused on addressing a critical challenge in this space: reducing latency in video streaming while maintaining quality of experience for users.
Our approach was novel---rather than compressing the entire video frame equally, we developed a human-centric methodology that prioritizes the human figure within frames and selectively transmits this data. This research presented an opportunity to examine existing industry-level video communication tools, as well as explore advanced image segmentation techniques related to the condensation of video streams.